Visual geolocalization (also known as Visual Place Recognition) is the task of recognizing the coarse geographical where an image was taken. This kind of spatial reasoning is an ability that is well developed and studied in humans. When we navigate in space we collect observations of the environment and organize them in a cognitive map, a unified representation of the spatial environment that we can access to support memory (e.g. to anchor a landmark or recognize where an image was taken) and guide our future actions (e.g., when we mentally plan a route to a destination). In visual geolocalization, the map of the known environment is built by collecting a database of images from the environment (the observations) and tagged with geograpical coordinates such as GPS (the organization). The goal of visual geolocalization is to develop automatic systems that are able to leverage this data to predict the location of an unseen image, with a desired spatial threshold. The threshold depends on the application, and it may go from few meters (street-level geolocalization) to thousands of kilometers (continent geolocalization). This ability is instrumental not only to create mobile robots that are capable of spatial reasoning and with advanced navigation skills, but it will enable also other applications such as assistive devices and systems that automatically categorize photo collections.
Figure 1. "Where is this place?" In visual geolocalization we answer this question, predicting the location where the image was taken with respect to a map.
In VANDAL we are working on the development of deep learning solutions to create more effective Visual Geolocalization systems. Here is a brief summary of our research in this field.
Studies and tools to support the research community
Research on Visual Geolocalization and Visual Place Recognition is growing very quickly across different communities – computer vision, robotics and machine learning. This makes it fundamental to take a step back and have a global look at where research is at now, in order to better guide it towards the next important questions. At the same time, it is important to sustain the research about these questions with new datasets. Some of our research is geared towards providing such support to the research community, in the form of surveys, benchmarks and datasets.
Surveys and Benchmarks
A Survey on Deep Visual Place Recognition (IEEE Access 2021) is a survey takes a snapshot of the field in the deep learning era, providing an overview of how visual geolocalization systems work and what are the main open challenges.
Deep Visual Geo-localization Benchmark (CVPR 2022) is a modular framework that has been developed to allow a fair evaluation of individual components in a visual geolocalization pipeline, across different datasets.
Figure 2. Deep Visual Geo-localization Benchmark website.
SF-XL is dataset introduced in Rethinking Visual Geo-localization for Large-Scale Applications (CVPR 2022) to support research on visual geolocalization on massive and densely sampled environments. This includes a database with over 40M images and two challenging sets of test queries, including a variety of weather, illumination and stylistic changes.
Robust visual geolocalization
One of the biggest challenges in visual geolocalization is the fact that the same place viewed at different times, in different weather conditions, and from slightly different angles may look substantially different. Making a visual geolocalization system robust to these variations and achieve good performance across different conditions and in presence of distractors or occlusions is a major topic of research. To address these problems, we are developing several solutions:
Figure 4. In visual geolocalization there is evidence that certain semantic elements are more stable across weather conditions and discriminative to recognize a plcae (e.g. buildings). Thus, the semantic content of an image can be leveraged to extract better image descriptors for the recognition of places. The architecture in this figure (from Learning Semantics for Visual Place Recognition through Multi-Scale Attention) uses a shared encoder with two heads, one for visual place recognition and the other for semantic segmentation, to learn global descriptors that are informed by semantics. At the same time, an attention module whose parameters are only affected by the geolocalization branch conditions the semantic module to focuse only on the parts of the image that are relevant for place recognition.
Scalable visual geolocalization
Until now visual geolocalization research has focused on recognizing the location of images in moderately sized geographical areas, such as a neighborhood or a single route in a city. However, to empower the promised real-world applications of this technology, such as enabling the navigation of autonomous agents, it will be necessary to scale this task to much wider areas with databases of spatially-densely sampled images. The question of scalability in visual geolocalization system not only demands for larger datasets, but it poses two problems: i) how to make the deployed system scalable at test time on a limited budget of memory and computational time, and ii) how to efficiently leverage these massive amounts of data at training time. We are focused on tackling these problem, and we have developed several solutions:
We are studying the impact of the dimensionality of the descriptors and of efficient indexing techniques on the memory requirements and retrieval time for geolocalization systems (Deep Visual Geo-localization Benchmark);
We have developed CosPlace, a new scalable training procedure for learning effective and compact global descriptors by using a classification task as proxy. This allows to avoid alltogether the expensive mining procedures typical of contrastive learning methods. CosPlace has set the new state-of-the-art on all the most popular place recognition datasets (Rethinking Visual Geo-localization for Large Scale Applications).
Figure 5. In CosPlace we use a classification task as a proxy to train the model that is used to extract the global descriptors for retrieving images from the same place as the query to geo-localize. For this purpose, naively dividing the environment in cells (left image) and using these cells as classes is not effective because i) images from adjaccent cells may see the same scene and thus be from the same place, and ii) the number of classes required to cover a large space will grow quickly. To solve these issues, CosPlace proposes a division of the space in sub-datasets (the slices with different colors in the image on the right), and the training iterates through the different sub-datasets, replacing the classification head. Images from Rethinking Visual Geo-localization for Large Scale Applications.
Visual place recognition from sequences of frames
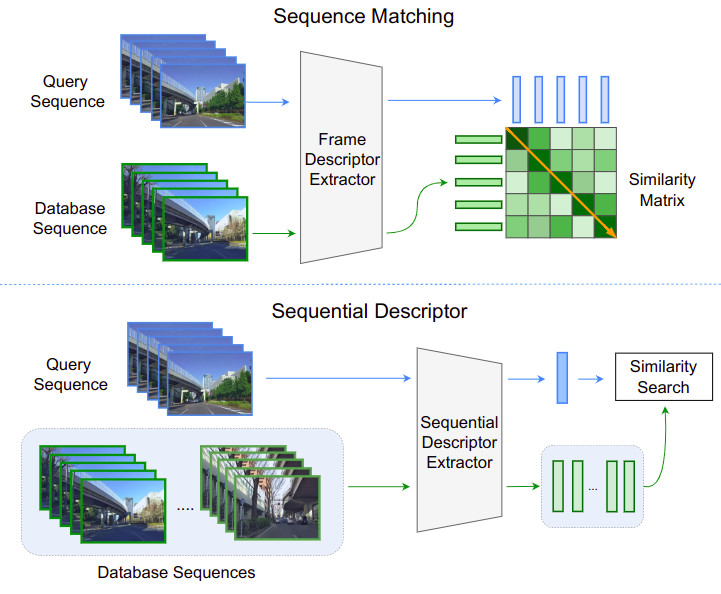
Visual place recognition is also widely studied in robotics where it serves as an important functional block of the localization and perception stack. In particular, it is used for loop closure in slam or to achieve coarse localization estimates. However, in this kind of applications the robot usually collects a stream of images from a camera, thus it would be advisable to also exploit the temporal information in this stream to undertand its location. Classical VPR methods have been built to leverage a single frame and expanding them to multi frames is not trivial. A popular and effective solution to this problem is is to perform sequence matching (see Fig. 6 top). First, each frame of the input sequence is individually compared to the collection of images of known places (referred to as database) to build a similarity matrix. Then, this matrix is searched for the most likely trajectory by aggregating the similarity scores. Yet searching the trajectory on the similarity matrix typically resorts to simplifying assumptions and complex machinery. A more recent approach is to use sequential descriptors that summarize sequences as a whole, thus enabling to directly perform a sequence-to-sequence similarity search (Fig. 6, bottom). This idea is alluring, not only for its efficiency but also because a sequential descriptor naturally incorporates the temproal information from the sequence, which provides more robustness to high-confidence false matches than single image descriptors. In Learning Sequential Descriptors for Sequence-Based Visual Place Recognition we have provided the first taxonomy of sequential descriptors for visual place recognition and we have proposed a novel aggregation layer, called SeqVLAD, that exploits the temporal cues in a sequence and leads to a new state of the art on multiple datasets
Figure 6. (Top) Sequence matching individually processes each frame in the sequences to extract single-image descriptors. The frame-to-frame similarity scores build a matrix, and the best matching sequence is determined by aggregating the scores in the matrix. (Bottom) With sequential descriptors, each sequence is mapped to a learned descriptor, and the best matching sequence is directly determined by measuring the sequence-to-sequence similarity Images from Learning Sequential Descriptors for Sequence-Based Visual Place Recognition.
Related Publications
Journal.
Learning Sequential Descriptors for Sequence-Based Visual Place Recognition
Mereu, Riccardo, Trivigno, Gabriele, Berton, Gabriele, Masone, Carlo, and Caputo, Barbara
In robotics, visual place recognition (VPR) is a continuous process that receives as input a video stream to produce a hypothesis of the robot’s current position within a map of known places. This work proposes a taxonomy of the architectures used to learn sequential descriptors for VPR, highlighting different mechanisms to fuse the information from the individual images. This categorization is supported by a complete benchmark of experimental results that provides evidence of the strengths and weaknesses of these different architectural choices. The analysis is not limited to existing sequential descriptors, but we extend it further to investigate the viability of Transformers instead of CNN backbones. We further propose a new ad-hoc sequence-level aggregator called SeqVLAD, which outperforms prior state of the art on different datasets. The code is available at https://github.com/vandal-vpr/vg-transformers.
@article{MereuTrivigno-2022,author={Mereu, Riccardo and Trivigno, Gabriele and Berton, Gabriele and Masone, Carlo and Caputo, Barbara},journal={IEEE Robotics and Automation Letters},title={Learning Sequential Descriptors for Sequence-Based Visual Place Recognition},year={2022},volume={7},number={4},pages={10383-10390},doi={10.1109/LRA.2022.3194310},url={https://doi.org/10.1109/LRA.2022.3194310},}
Journal.
Adaptive-Attentive Geolocalization From Few Queries: A Hybrid Approach
Paolicelli, Valerio, Berton, Gabriele, Montagna, Francesco, Masone, Carlo, and Caputo, Barbara
We tackle the task of cross-domain visual geo-localization, where the goal is to geo-localize a given query image against a database of geo-tagged images, in the case where the query and the database belong to different visual domains. In particular, at training time, we consider having access to only few unlabeled queries from the target domain. To adapt our deep neural network to the database distribution, we rely on a 2-fold domain adaptation technique, based on a hybrid generative-discriminative approach. To further enhance the architecture, and to ensure robustness across domains, we employ a novel attention layer that can easily be plugged into existing architectures. Through a large number of experiments, we show that this adaptive-attentive approach makes the model robust to large domain shifts, such as unseen cities or weather conditions. Finally, we propose a new large-scale dataset for cross-domain visual geo-localization, called SVOX.
@article{Paolicelli-2022b,author={Paolicelli, Valerio and Berton, Gabriele and Montagna, Francesco and Masone, Carlo and Caputo, Barbara},title={Adaptive-Attentive Geolocalization From Few Queries: A Hybrid Approach},journal={Frontiers in Computer Science},volume={4},year={2022},url={https://www.frontiersin.org/article/10.3389/fcomp.2022.841817},doi={10.3389/fcomp.2022.841817},issn={2624-9898},}
Conference Proc.
Learning Semantics for Visual Place Recognition through Multi-Scale Attention
Paolicelli, V., Tavera, A., Berton, G., Masone, C., and Caputo, B.
In Proceedings of the 21st International Conference on Image Analysis and Processing (ICIAP) 2022
In this paper we address the task of visual place recognition (VPR), where the goal is to retrieve the correct GPS coordinates of a given query image against a huge geotagged gallery. While recent works have shown that building descriptors incorporating semantic and appearance information is beneficial, current state-of-the-art methods opt for a top down definition of the significant semantic content. Here we present the first VPR algorithm that learns robust global embeddings from both visual appearance and semantic content of the data, with the segmentation process being dynamically guided by the recognition of places through a multi-scale attention module. Experiments on various scenarios validate this new approach and demonstrate its performance against state-of-the-art methods. Finally, we propose the first synthetic-world dataset suited for both place recognition and segmentation tasks.
@inproceedings{Paolicelli-2022,author={Paolicelli, V. and Tavera, A. and Berton, G. and Masone, C. and Caputo, B.},title={Learning Semantics for Visual Place Recognition through Multi-Scale Attention},booktitle={Proceedings of the 21st International Conference on Image Analysis and Processing (ICIAP)},year={2022},pages={},}
Conference Proc.
Rethinking Visual Geo-localization for Large-Scale Applications
Berton, G., Masone, C., and Caputo, B.
In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2022
Visual Geo-localization (VG) is the task of estimating the position where a given photo was taken by comparing it with a large database of images of known locations. To investigate how existing techniques would perform on a real-world city-wide VG application, we build San Francisco eXtra Large, a new dataset covering a whole city and providing a wide range of challenging cases, with a size 30x bigger than the previous largest dataset for visual geo-localization. We find that current methods fail to scale to such large datasets, therefore we design a new highly scalable training technique, called CosPlace, which casts the training as a classification problem avoiding the expensive mining needed by the commonly used contrastive learning. We achieve state-of-the-art performance on a wide range of datasets and find that CosPlace is robust to heavy domain changes. Moreover, we show that, compared to the previous state-of-the-art, CosPlace requires roughly 80% less GPU memory at train time, and it achieves better results with 8x smaller descriptors, paving the way for city-wide real-world visual geo-localization.
@inproceedings{Berton-2022,author={Berton, G. and Masone, C. and Caputo, B.},title={Rethinking Visual Geo-localization for Large-Scale Applications},booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},year={2022},pages={},}
Conference Proc. Oral
Deep Visual Geo-localization Benchmark
Berton, G., Mereu, R., Trivigno, G., Masone, C., Csurka, G., Sattler, T., and Caputo, B.
In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2022
In this paper, we propose a new open-source benchmarking framework for Visual Geo-localization (VG) that allows to build, train, and test a wide range of commonly used architectures, with the flexibility to change individual components of a geo-localization pipeline. The purpose of this framework is twofold: i) gaining insights into how different components and design choices in a VG pipeline impact the final results, both in terms of performance (recall@N metric) and system requirements (such as execution time and memory consumption); ii) establish a systematic evaluation protocol for comparing different methods. Using the proposed framework, we perform a large suite of experiments which provide criteria for choosing backbone, aggregation and negative mining depending on the use-case and requirements. We also assess the impact of engineering techniques like pre/post-processing, data augmentation and image resizing, showing that better performance can be obtained through somewhat simple procedures: for example, downscaling the images’ resolution to 80% can lead to similar results with a 36% savings in extraction time and dataset storage requirement.
@inproceedings{Berton-2022b,author={Berton, G. and Mereu, R. and Trivigno, G. and Masone, C. and Csurka, G. and Sattler, T. and Caputo, B.},title={Deep Visual Geo-localization Benchmark},booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},year={2022},pages={},}
Conference Proc.
Adaptive-Attentive Geolocalization from few queries: a hybrid approach
Moreno Berton, G., Paolicelli, V., Masone, C., and Caputo, B.
In 2021 IEEE Winter Conference on Applications of Computer Vision (WACV) 2021
We address the task of cross-domain visual place recognition, where the goal is to geolocalize a given query image against a labeled gallery, in the case where the query and the gallery belong to different visual domains. To achieve this, we focus on building a domain robust deep network by leveraging over an attention mechanism combined with few-shot unsupervised domain adaptation techniques, where we use a small number of unlabeled target domain images to learn about the target distribution. With our method, we are able to outperform the current state of the art while using two orders of magnitude less target domain images. Finally we propose a new large-scale dataset for cross-domain visual place recognition, called SVOX.
@inproceedings{Berton-2021,author={{Moreno Berton}, G. and Paolicelli, V. and Masone, C. and Caputo, B.},booktitle={2021 IEEE Winter Conference on Applications of Computer Vision (WACV)},title={Adaptive-Attentive Geolocalization from few queries: a hybrid approach},year={2021},volume={},number={},pages={2917-2926},doi={10.1109/WACV48630.2021.00296},}
Conference Proc.
Viewpoint Invariant Dense Matching for Visual Geolocalization
Berton, G., Masone, C., Paolicelli, V., and Caputo, B.
In 2021 IEEE/CVF International Conference on Computer Vision (ICCV) 2021
In this paper we propose a novel method for image matching based on dense local features and tailored for visual geolocalization. Dense local features matching is robust against changes in illumination and occlusions, but not against viewpoint shifts which are a fundamental aspect of geolocalization. Our method, called GeoWarp, directly embeds invariance to viewpoint shifts in the process of extracting dense features. This is achieved via a trainable module which learns from the data an invariance that is meaningful for the task of recognizing places. We also devise a new self-supervised loss and two new weakly supervised losses to train this module using only unlabeled data and weak labels. GeoWarp is implemented efficiently as a re-ranking method that can be easily embedded into pre-existing visual geolocalization pipelines. Experimental validation on standard geolocalization benchmarks demonstrates that GeoWarp boosts the accuracy of state-of-the-art retrieval architectures.
@inproceedings{Berton-2021b,author={Berton, G. and Masone, C. and Paolicelli, V. and Caputo, B.},booktitle={2021 IEEE/CVF International Conference on Computer Vision (ICCV)},title={Viewpoint Invariant Dense Matching for Visual Geolocalization},year={2021},volume={},number={},pages={12149-12158},doi={10.1109/ICCV48922.2021.01195},}
In recent years visual place recognition (VPR), i.e., the problem of recognizing the location of images, has received considerable attention from multiple research communities, spanning from computer vision to robotics and even machine learning. This interest is fueled on one hand by the relevance that visual place recognition holds for many applications and on the other hand by the unsolved challenge of making these methods perform reliably in different conditions and environments. This paper presents a survey of the state-of-the-art of research on visual place recognition, focusing on how it has been shaped by the recent advances in deep learning. We start discussing the image representations used in this task and how they have evolved from using hand-crafted to deep-learned features. We further review how metric learning techniques are used to get more discriminative representations, as well as techniques for dealing with occlusions, distractors, and shifts in the visual domain of the images. The survey also provides an overview of the specific solutions that have been proposed for applications in robotics and with aerial imagery. Finally the survey provides a summary of datasets that are used in visual place recognition, highlighting their different characteristics.
@article{Masone-2021,author={Masone, C. and Caputo, B.},journal={IEEE Access},title={A Survey on Deep Visual Place Recognition},year={2021},volume={9},number={},pages={19516-19547},doi={10.1109/ACCESS.2021.3054937},}







 Journal.
Journal.  Journal.
Journal. 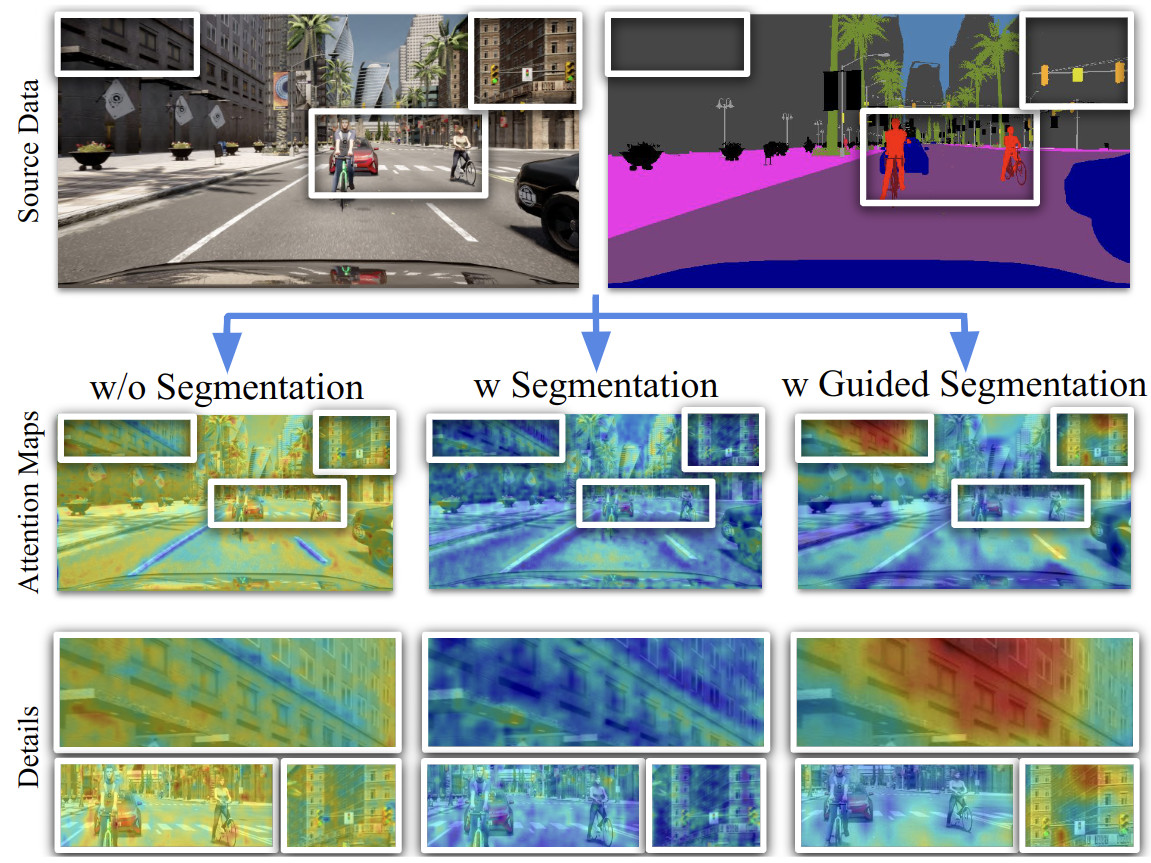 Conference Proc.
Conference Proc. 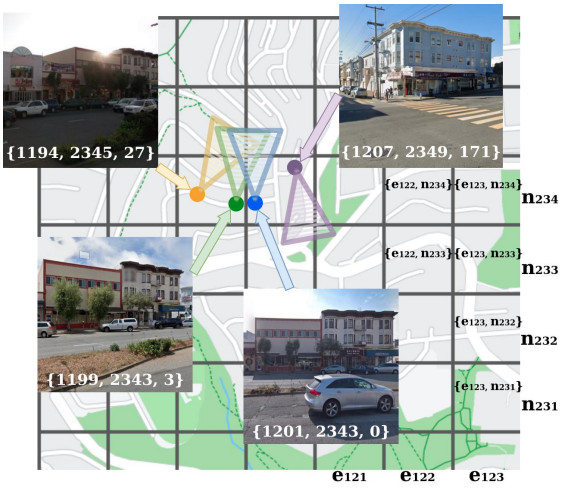 Conference Proc.
Conference Proc. 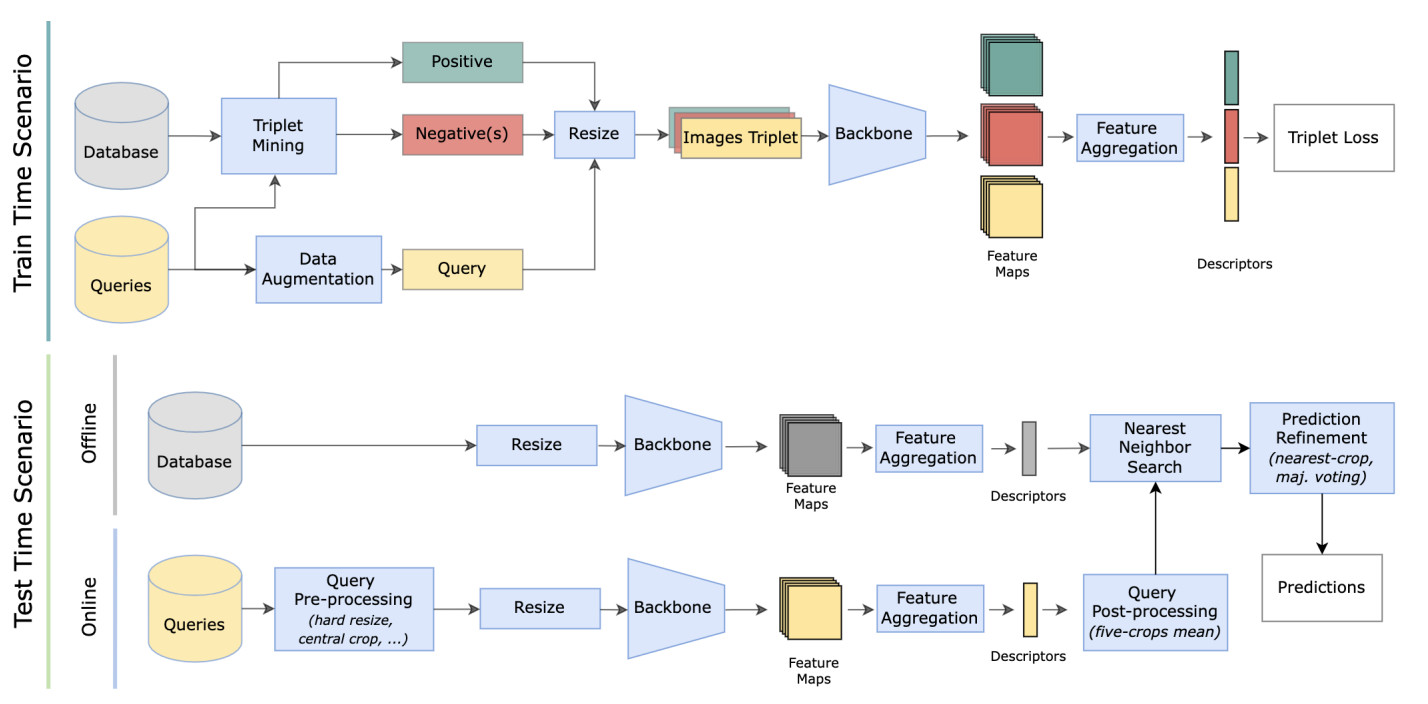 Conference Proc.
Conference Proc.  Conference Proc.
Conference Proc.  Conference Proc.
Conference Proc. 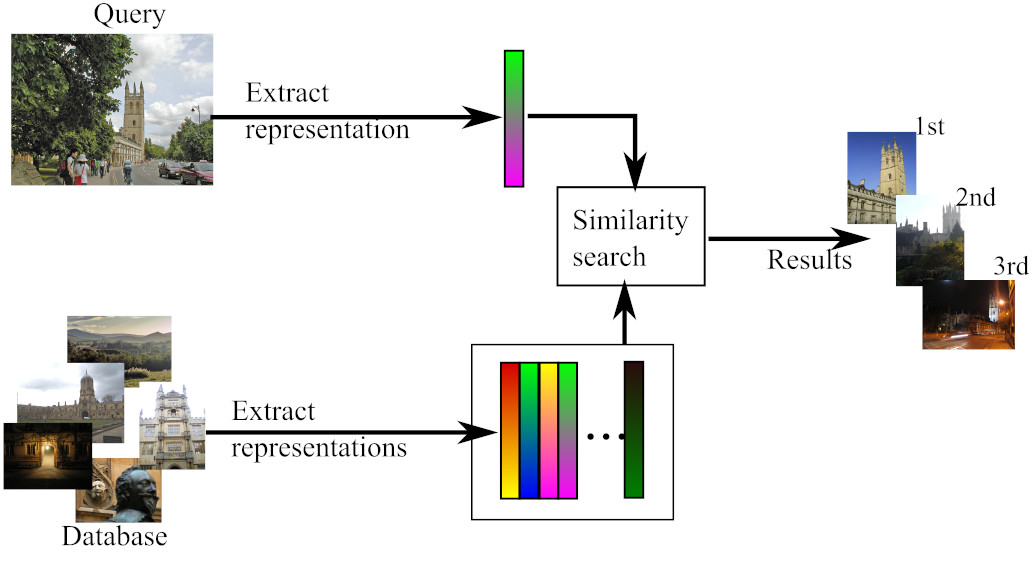 Journal
Journal