Figure 1. Example of semantic segmentation from an RGB image in a driving scenario Image from the Cityscapes dataset.
The fine grained understanding of the visual content in images provided by semantic segmentation finds application in different fields. I particularly interestd in its application to driving scenes and aerial imagery, which are extremely relevant in todays industry (e.g., for autonomous driving, crops monitoring, etc.). Within this contexts, we are investigating solutions to improve the segmenttion results even when the models are applied to different target domains with respect to the distribution of data available at training time (domain shift problem). Although this problem affects also other tasks, in vsemantic segmentation it is exacerbated by the fact that labeling the images with pixel-wise annotations is very expensive and time consuming. Thus, expanding the training set with images from many different domains is infeasible not only for the difficulty in collecting the images, but also in labeling them.
Semantic Segmentation for Autonomous Driving
Athough semantic segmentation holds the potential to be an extremely important functionality in the perception stack of a self-driving car, its effectiveness depends on wether or not it can adapt or generalize to unseen domains. This problem is crucial if we want to achieve the promise of autonomous vehicles that are capable to operate anywhere in the world. To support this research, at Vandal we have created a synthetic dataset, called IDDA, which contains 105 different scenarios that differentiate for the weather condition, environment and point of view of the camera.
Figure 2.IDDA offers 105 scenarios of driving scenes, with weather conditions, environments and points of view of the camera (on a car, jeep, mini van, ...). Each RGB images is accompanied by a semantic mask and depth image.
We have openly released IDDA as a tool to study and develop domain adaptation and generalization solutions for semantic segmentation in driving scenes. More info can be found in our RA-L paper IDDA: A Large-Scale Multi-Domain Dataset for Autonomous Driving.
For example, one of the solutions that we have developed also leveraging this dataset is PixDA, a few-shot method for cross-domain alignment in semantic segmentation. More info on PixDA can be found in our WACV 2021 paper Pixel-by-Pixel Cross-Domain Alignment for Few-Shot Semantic Segmentation. The idea behind PixDA is that a few-shot solution where the training dataset includes only a few labeled images from the target domain may be more practical than an unsupervised domain algorithm that requires a very large number of unlabeled target images. Yet, the few-shot setting is very challenging because it can significantly increase the class imbalance between source and target data. In fact, although an imbalance in the available pixels-per class is typical in semantic segmentation (because some classes are very extended, and other small), in the few-shot setting the target images may expose very few pixels from some classes, or even none at all. Moreover, an image wise domain alignment of the features can produce a negative transfer on some semantic categories that are already well aligned across the two domains. PixDA uses a new loss, called PixAdv, that aligns source and target domains locally while reducing negative transfer and avoiding overfitting the underrepresented classes.
Figure 3. Illustration of the pixel-by-pixel adversarial learning of PixDA. A new pixel-wise discriminator computes the adversarial loss whose contribution at each pixel is weighted by two terms: S, that considers the ability of the model to correctly represent the pixel, and B, that weights each pixel based on the frequency of its semantic class. Yellow/blue lines refer to the source/target domain, respectively.
Semantic Segmentation for Aerial Monitoring and Remote Sensing
The large availability of data for driving scenes has led to new and more effective semantic segmentation architectures. However, these same solutions are generally less effective when used to process aerial images. In our research we have found that the peculiarities of aerial images may be the cause for this phenomenon and may require more specific solutions rather then applying models developed for driving scenes. In particular, the model the model cannot rely on a fixed semantic structure of the scene, unlike in driving scenes where the street is always at the bottom, the sky on top, etcetera. Moreover, there is an even more pronounced imbalance among classes, with some that are much more extended than other (for example land covers versus cars). We are developing solutions that address the domain shift problem in aerial segmentation and are tailored to address the specificities of these scenes.
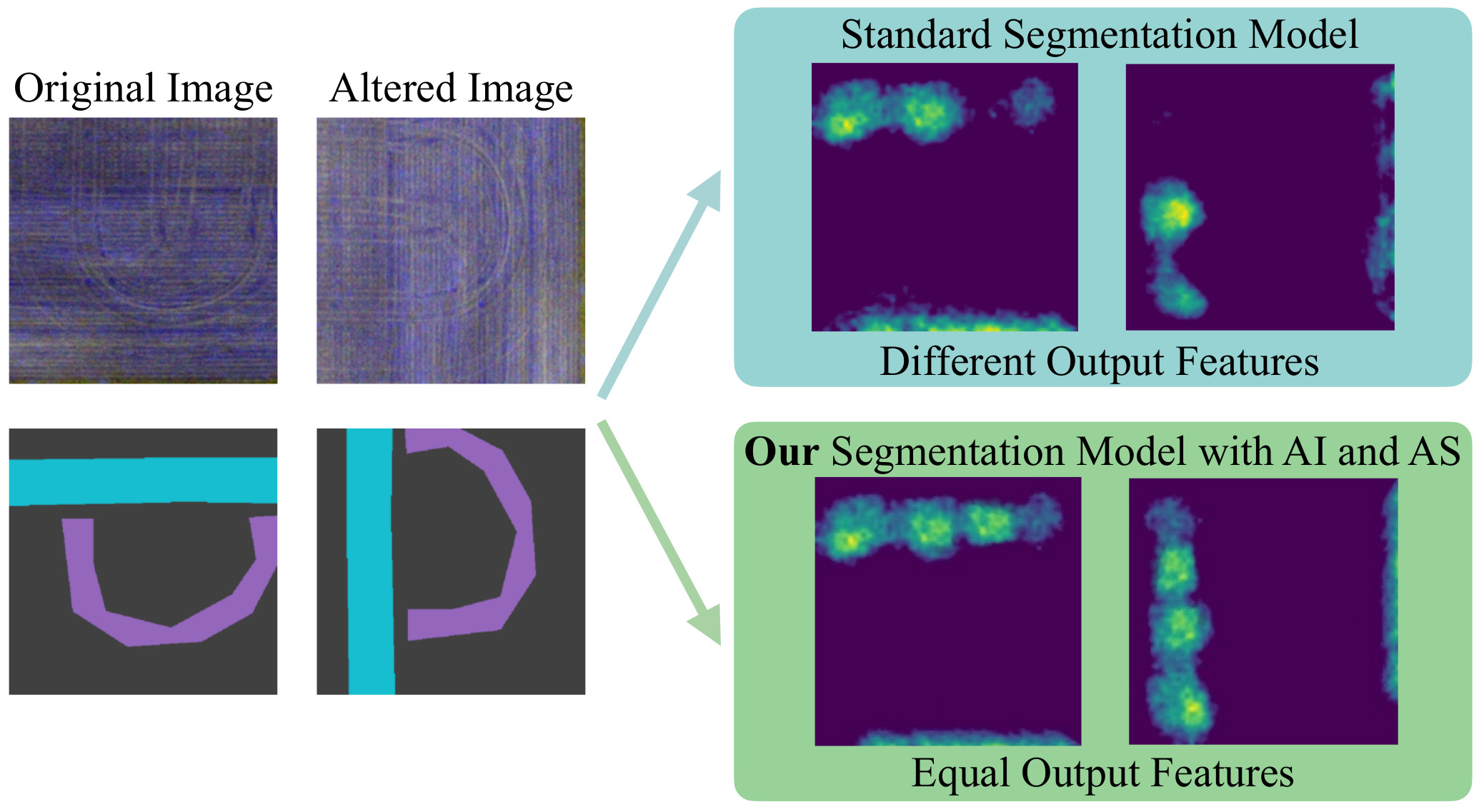
In this paper, we investigate the problem of Semantic Segmentation for agricultural aerial imagery. We observe that the existing methods used for this task are designed without considering two characteristics of the aerial data: (i) the top-down perspective implies that the model cannot rely on a fixed semantic structure of the scene, because the same scene may be experienced with different rotations of the sensor; (ii) there can be a strong imbalance in the distribution of semantic classes because the relevant objects of the scene may appear at extremely different scales (e.g., a field of crops and a small vehicle). We propose a solution to these problems based on two ideas: (i) we use together a set of suitable augmentation and a consistency loss to guide the model to learn semantic representations that are invariant to the photometric and geometric shifts typical of the top-down perspective (Augmentation Invariance); (ii) we use a sampling method (Adaptive Sampling) that selects the training images based on a measure of pixel-wise distribution of classes and actual network confidence. With an extensive set of experiments conducted on the Agriculture-Vision dataset, we demonstrate that our proposed strategies improve the performance of the current state-of-the-art method.
@inproceedings{Tavera-2022,author={Tavera, A. and Arnaudo, E. and Masone, C. and Caputo, B.},title={Augmentation Invariance and Adaptive Sampling in Semantic Segmentation of Agricultural Aerial Images},booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops},year={2022},pages={},}
Conference Proc.
Learning Semantics for Visual Place Recognition through Multi-Scale Attention
Paolicelli, V., Tavera, A., Berton, G., Masone, C., and Caputo, B.
In Proceedings of the 21st International Conference on Image Analysis and Processing (ICIAP) 2022
In this paper we address the task of visual place recognition (VPR), where the goal is to retrieve the correct GPS coordinates of a given query image against a huge geotagged gallery. While recent works have shown that building descriptors incorporating semantic and appearance information is beneficial, current state-of-the-art methods opt for a top down definition of the significant semantic content. Here we present the first VPR algorithm that learns robust global embeddings from both visual appearance and semantic content of the data, with the segmentation process being dynamically guided by the recognition of places through a multi-scale attention module. Experiments on various scenarios validate this new approach and demonstrate its performance against state-of-the-art methods. Finally, we propose the first synthetic-world dataset suited for both place recognition and segmentation tasks.
@inproceedings{Paolicelli-2022,author={Paolicelli, V. and Tavera, A. and Berton, G. and Masone, C. and Caputo, B.},title={Learning Semantics for Visual Place Recognition through Multi-Scale Attention},booktitle={Proceedings of the 21st International Conference on Image Analysis and Processing (ICIAP)},year={2022},pages={},}
Conference Proc.
Pixel-by-Pixel Cross-Domain Alignment for Few-Shot Semantic Segmentation
Tavera, A., Cermelli, F., Masone, C., and Caputo, B.
In 2022 IEEE Winter Conference on Applications of Computer Vision (WACV) 2022
In this paper we consider the task of semantic segmentation in autonomous driving applications. Specifically, we consider the cross-domain few-shot setting where training can use only few real-world annotated images and many annotated synthetic images. In this context, aligning the domains is made more challenging by the pixel-wise class imbalance that is intrinsic in the segmentation and that leads to ignoring the underrepresented classes and overfitting the well represented ones. We address this problem with a novel framework called Pixel-By-Pixel Cross-Domain Alignment (PixDA). We propose a novel pixel-by-pixel domain adversarial loss following three criteria: (i) align the source and the target domain for each pixel, (ii) avoid negative transfer on the correctly represented pixels, and (iii) regularize the training of infrequent classes to avoid overfitting. The pixel-wise adversarial training is assisted by a novel sample selection procedure, that handles the imbalance between source and target data, and a knowledge distillation strategy, that avoids overfitting towards the few target images. We demonstrate on standard synthetic-to-real benchmarks that PixDA outperforms previous state-of-the-art methods in (1-5)-shot settings.
@inproceedings{Tavera-2022b,author={Tavera, A. and Cermelli, F. and Masone, C. and Caputo, B.},title={Pixel-by-Pixel Cross-Domain Alignment for Few-Shot Semantic Segmentation},booktitle={2022 IEEE Winter Conference on Applications of Computer Vision (WACV)},year={2022},pages={1626-1635},}
Conference Proc.
Reimagine BiSeNet for Real-Time Domain Adaptation in Semantic Segmentation
Semantic segmentation models have reached remarkable performance across various tasks. However, this performance is achieved with extremely large models, using powerful computational resources and without considering training and inference time. Real-world applications, on the other hand, necessitate models with minimal memory demands, efficient inference speed, and executable with low-resources embedded devices, such as self-driving vehicles. In this paper, we look at the challenge of real-time semantic segmentation across domains, and we train a model to act appropriately on real-world data even though it was trained on a synthetic realm. We employ a new lightweight and shallow discriminator that was specifically created for this purpose. To the best of our knowledge, we are the first to present a real-time adversarial approach for assessing the domain adaption problem in semantic segmentation. We tested our framework in the two standard protocol: GTA5 to Cityscapes and SYNTHIA to Cityscapes.
@inproceedings{Tavera-2021,author={Tavera, A. and Masone, C. and Caputo, B.},title={Reimagine BiSeNet for Real-Time Domain Adaptation in Semantic Segmentation},booktitle={Proceedings of the I-RIM 2021 Conference},year={2021},pages={},}
Journal
IDDA: A Large-Scale Multi-Domain Dataset for Autonomous Driving
Alberti, E., Tavera, A., Masone, C., and Caputo, B.
Semantic segmentation is key in autonomous driving. Using deep visual learning architectures is not trivial in this context, because of the challenges in creating suitable large scale annotated datasets. This issue has been traditionally circumvented through the use of synthetic datasets, that have become a popular resource in this field. They have been released with the need to develop semantic segmentation algorithms able to close the visual domain shift between the training and test data. Although exacerbated by the use of artificial data, the problem is extremely relevant in this field even when training on real data. Indeed, weather conditions, viewpoint changes and variations in the city appearances can vary considerably from car to car, and even at test time for a single, specific vehicle. How to deal with domain adaptation in semantic segmentation, and how to leverage effectively several different data distributions (source domains) are important research questions in this field. To support work in this direction, this letter contributes a new large scale, synthetic dataset for semantic segmentation with more than 100 different source visual domains. The dataset has been created to explicitly address the challenges of domain shift between training and test data in various weather and view point conditions, in seven different city types. Extensive benchmark experiments assess the dataset, showcasing open challenges for the current state of the art.
@article{Alberti-2020,author={Alberti, E. and Tavera, A. and Masone, C. and Caputo, B.},journal={IEEE Robotics and Automation Letters},title={IDDA: A Large-Scale Multi-Domain Dataset for Autonomous Driving},year={2020},volume={5},number={4},pages={5526-5533},doi={10.1109/LRA.2020.3009075},}





 Workshop Proc.
Workshop Proc. 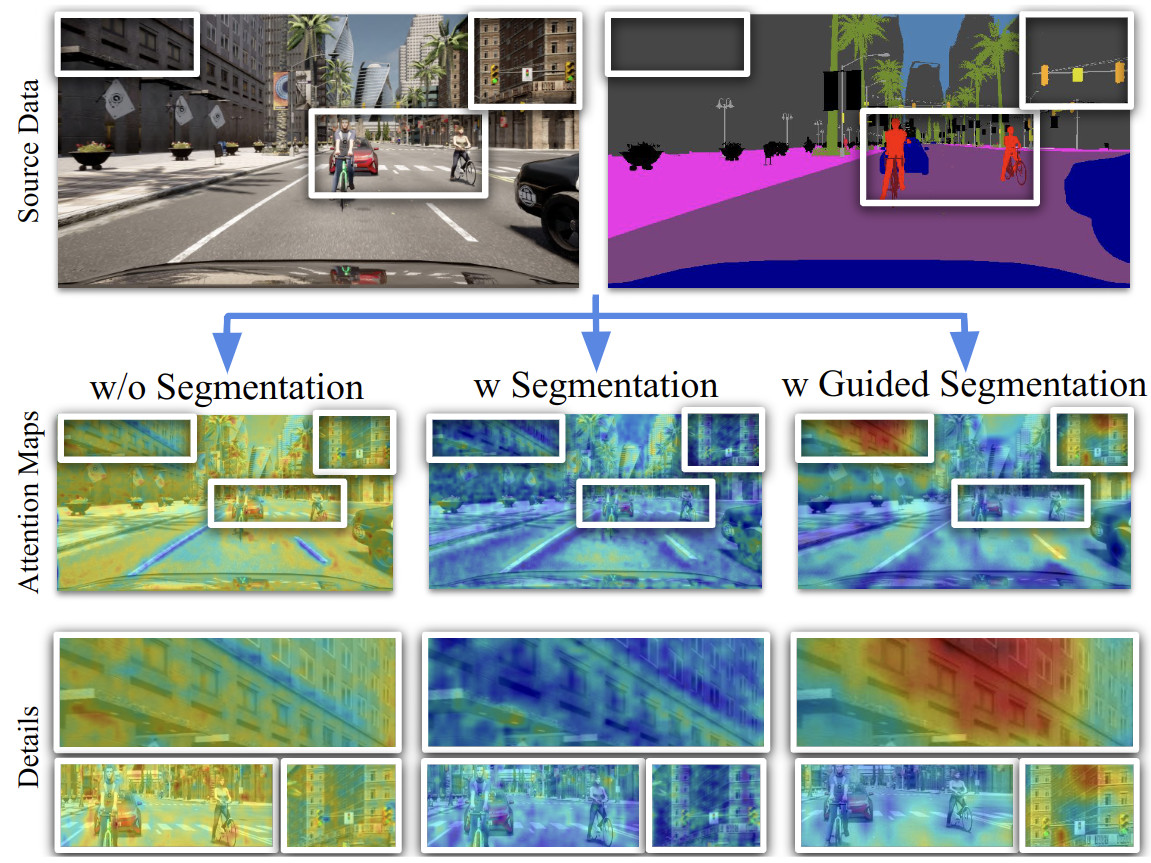 Conference Proc.
Conference Proc. 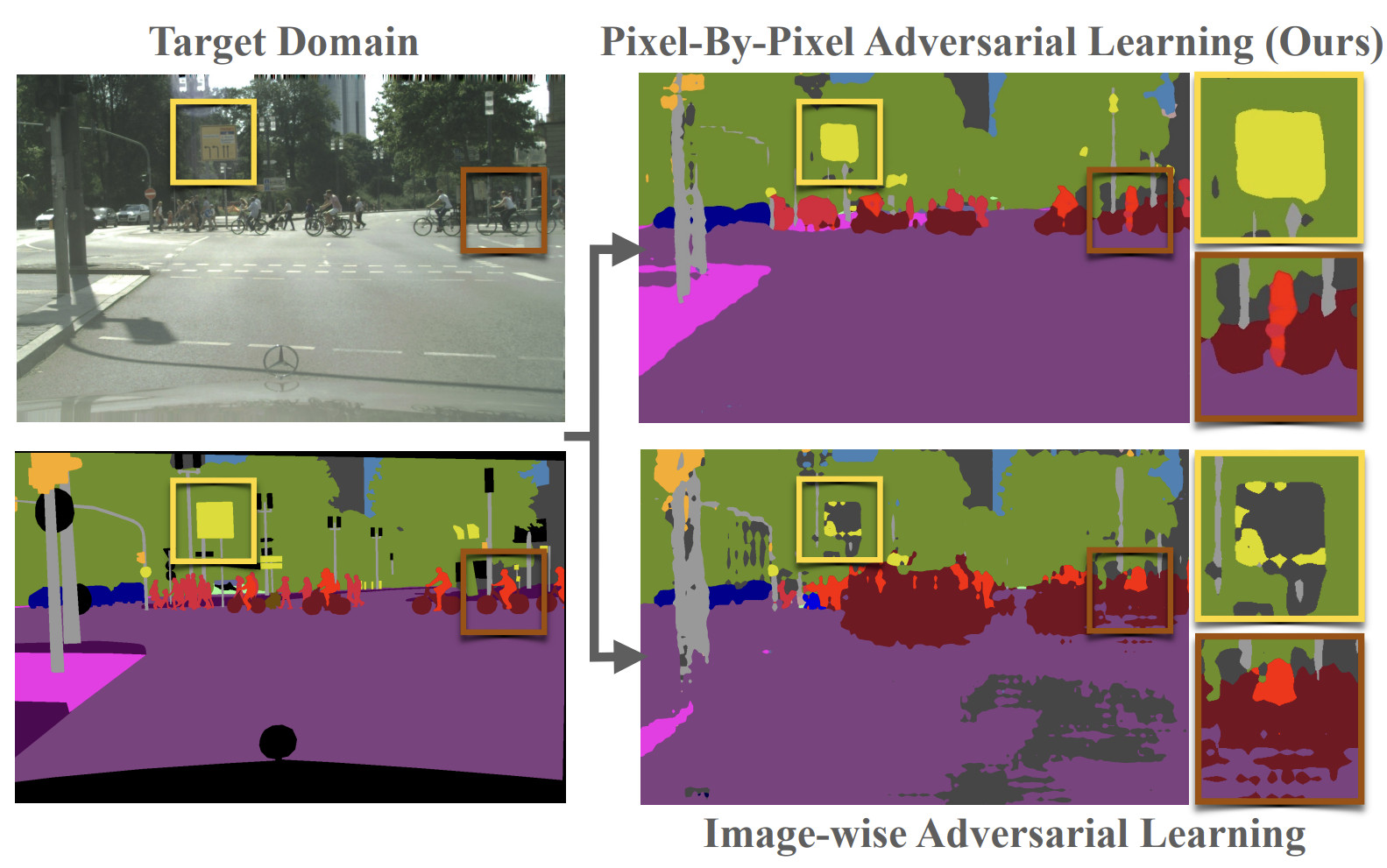 Conference Proc.
Conference Proc. 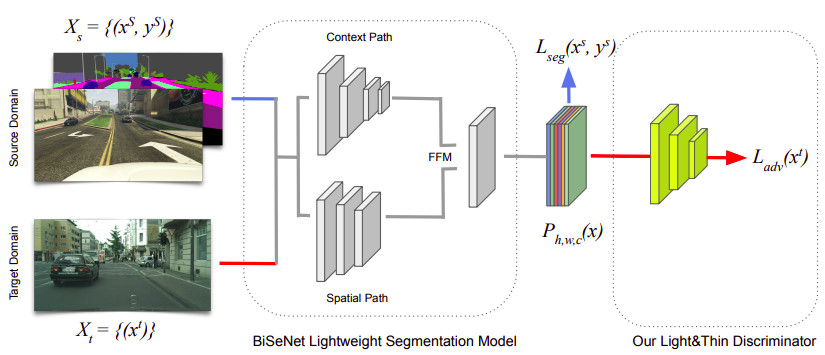 Conference Proc.
Conference Proc.  Journal
Journal